Wayback machine online downloader with CMS.
Restore a fully functional copy of your site!
If you are first here and did not see how our system works we have prepared a test recovery for you.
To see the recovery locally without using hosting, we recommend installing XAMPP server on your computer. During installation, you only need to select Apache and PHP.
To see the recovery locally without using hosting, we recommend installing XAMPP server on your computer. During installation, you only need to select Apache and PHP.
Restore prices
Website has
up to 200 files
- Sites that contain up to 200 files cost only $0.25.
Website has
201-1200 files
- Most of the websites that restore our users contain up to 1000 files and cost less than $4.
Website has
more than 1200 files
- If the site you need contains more than 1200 files, then each additional thousand files will cost only one dollar.
Website downloader and Content Management System (CMS) existing site converter.
Download a fully functional copy of the site!
Ability to download .onion sites!
If you are first here and did not see how our system works we have prepared a test recovery for you.
To see the recovery locally without using hosting, we recommend installing XAMPP server on your computer. During installation, you only need to select Apache and PHP.
To see the recovery locally without using hosting, we recommend installing XAMPP server on your computer. During installation, you only need to select Apache and PHP.
Download prices
Website has
up to 200 files
- Sites that contain up to 200 files cost only $0.25.
Website has
201-1200 files
- Most of the sites downloaded by our users contain up to 1000 files and cost less than $4.
Website has
more than 1200 files
- If the site you need contains more than 1200 files, then each additional thousand files will cost only one dollar.
Latest Blog Articles:
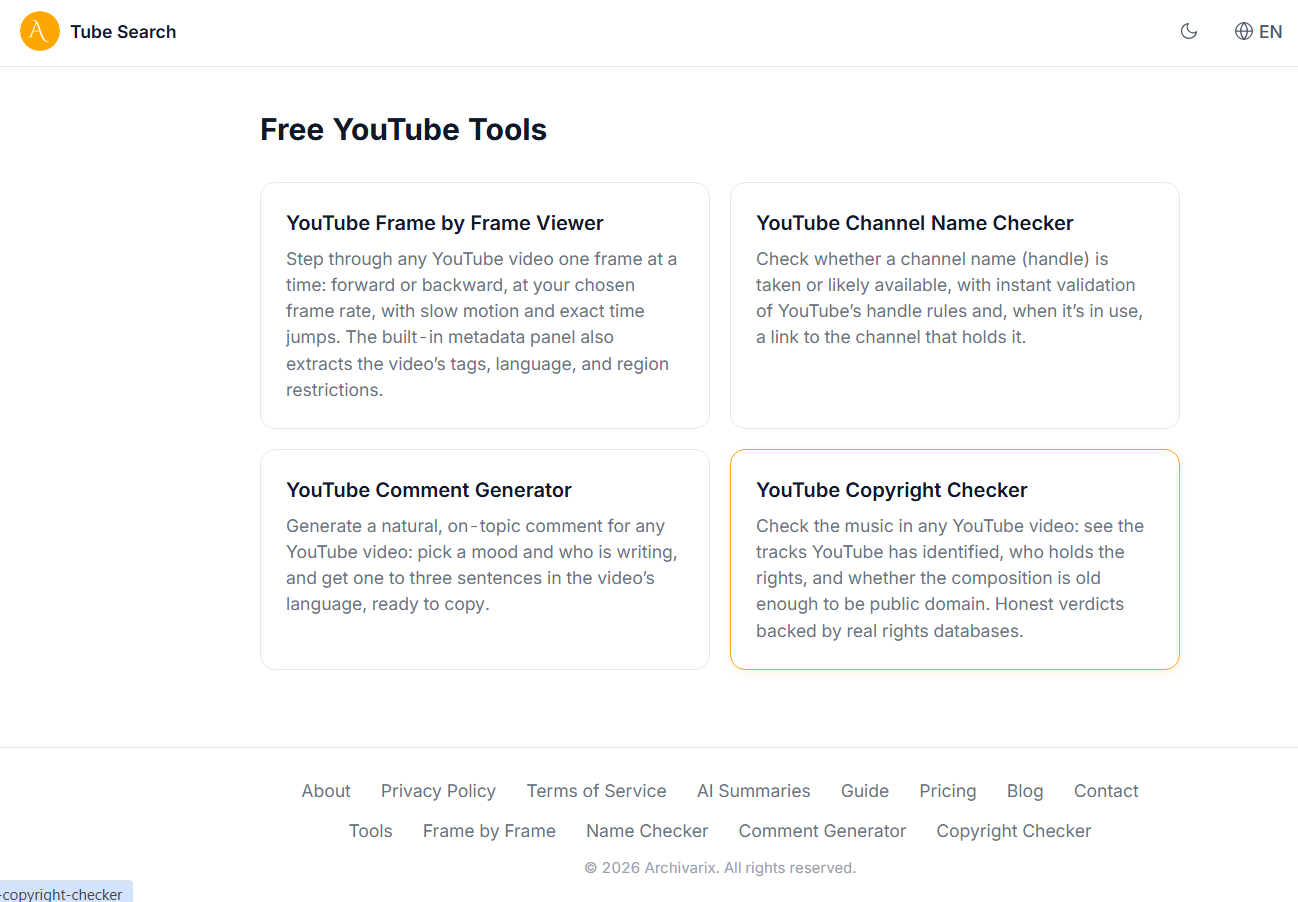
Free YouTube Tools on Tube Search: Frame by Frame Viewer, Tags, Name Checker and Copyright Checker
Tube Search now has a section of free YouTube tools. These are small utilities that solve specific everyday tasks: stepping through a video frame by frame, extracting hidden tags, checking whether a channel name is taken, writing a comment, or figuring out the copyright status of the music in a video. Everything runs right in the browser, no installation and no signup. Here is what each tool does and who it is for.
Read more…
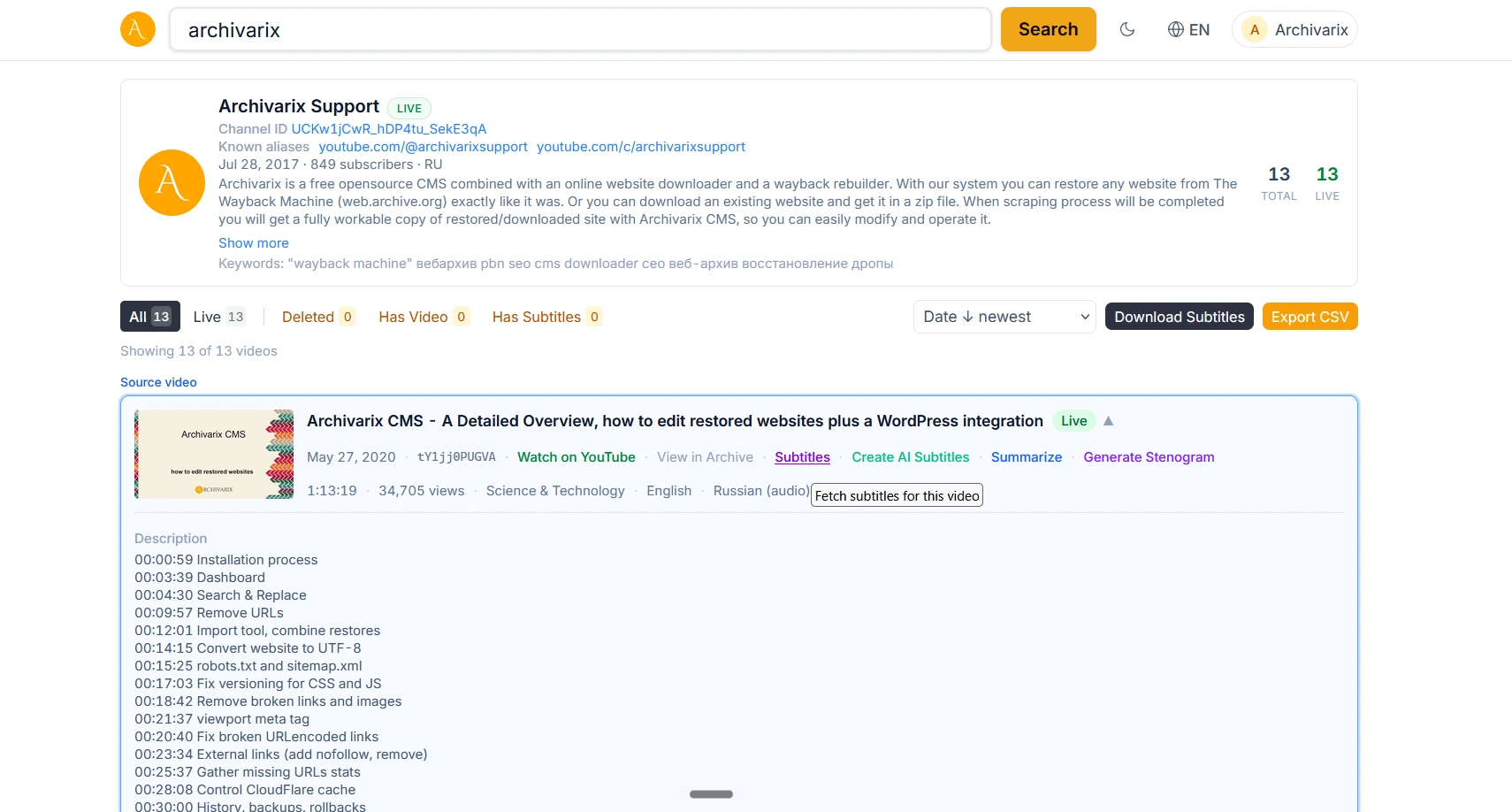
How to Download YouTube Subtitles, Even from Deleted Videos
You found the video you needed on YouTube, but you do not want to watch the whole thing just for a couple of lines. Or you need the text of a lecture to translate it, quote it, or simply skim through it. YouTube subtitles solve this, but copying them from the site itself is not easy: the interface gives you no download button, and third-party services often break or ask for payment. Archivarix Tube Search has a simple way to get the subtitles of any video, and more importantly, it works even for clips that have already been removed from YouTube.
Read more…
How long does a web page live: what the research says about link rot
Open any article from a decade ago and click through the links in it. There is a good chance that some of them lead nowhere. Instead of the page you wanted, you get a 404 error, a parked domain advertising cheap insurance, or a redirect to someone else's site. This phenomenon is called link rot, and it is far more widespread than people tend to assume.
Read more…
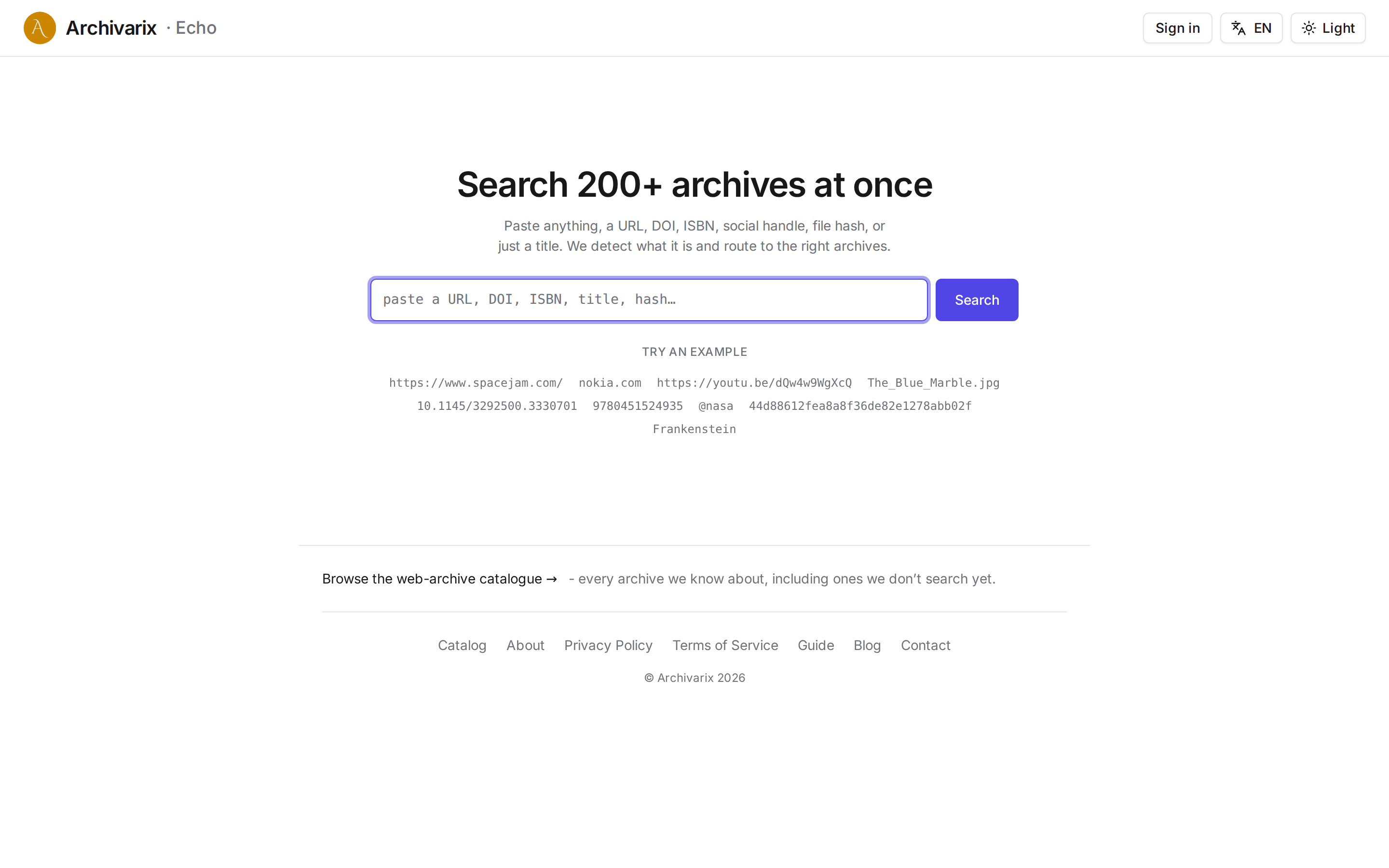
Archivarix Echo: check 200+ web archives with one search
The web keeps falling apart. Pages go offline, accounts get deleted, papers slip behind paywalls, projects shut down. Usually a copy survives somewhere, in the Wayback Machine, archive.today, Common Crawl, scholarly indexes like Crossref, libraries like Open Library, and hundreds of smaller subject-specific archives. The catch is that they are all separate. To find out where something was saved, you used to open them one at a time: Wayback first, then archive.today, then a dozen academic and book databases.
Read more…
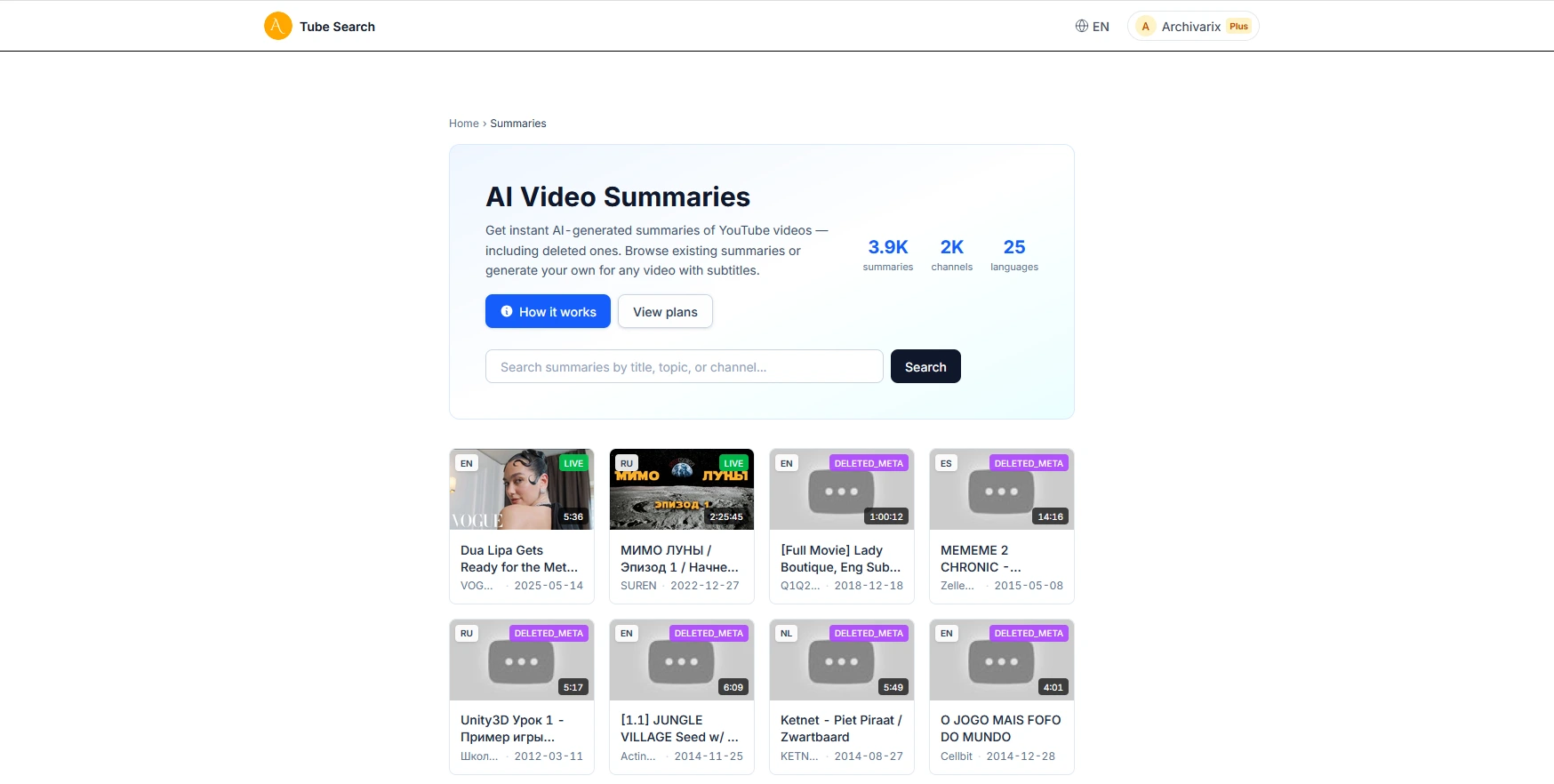
AI Video Summaries in Archivarix Tube Search
When you find a deleted YouTube video through Tube Search, you typically get metadata: a title, description, upload date, and sometimes subtitles. That is already useful. But reading through raw subtitles to understand what a video was about takes time, especially for longer recordings.
We have added AI-powered video summaries to Tube Search. If a video has archived subtitles, the system can now generate a structured summary of its content in seconds.
Read more…
We have added AI-powered video summaries to Tube Search. If a video has archived subtitles, the system can now generate a structured summary of its content in seconds.